SDD 0008 - Platform Configuration Management
Author |
Marco Fretz |
Owner |
Marco Fretz |
Reviewers (SIG) |
|
Date |
2019-10-18 |
Status |
obsolete |
|
Summary
This is the concept on how we manage a Kubernetes cluster after it’s up an running. |
Motivation
Most providers and Kubernetes cluster management frameworks and concepts end when the cluster is up and running. To achieve feature parity with the VMSFv1 (Puppet manged world) we need to do more.
We want to have one source of truth when configuring all aspects of a VSHN Managed Platform.
Goals
-
Manage (provisioned and configured) all things needed to be a SYN Managed Platform, e.g.:
-
The SYN management framework (Steward, flux)
-
The Monitoring framework
-
Backup framework
-
Crossplane CRDs and Operators
-
Managed Services (Postgres, MySQL, Redis, …) operators, when running on a Cloud which doesn’t provide such services
-
cert-manager
-
Vault
-
…
-
-
Have cross customer and cluster sane defaults for all the configured services, while still having a easy way to overwrite per provider, distribution, cluster, customer, project, etc.
-
Versioning of the components / services and straight forward selection of which version is used where
Design Proposal
Terminology
-
Output Repo is where the generated Kubernetes manifests and Kapitan secret files are stored, ready to be used by GitOps on the target cluster
-
Input Repo is where cluster / customer specific overrides can be committed to
-
Config Repo is where the global configuration is stored
-
Target Cluster is the Kubernetes cluster that’s managed
-
Commodore A tool built around Kapitan which uses a Puppet Hiera like approach to fetch configuration and components from different source (Input Repo, SYNventory, Config repos to render jsonnet templates to produce the Kubernetes manifests, the Catalog.
-
Components are repos containing bundles of Kapitan classes and templates which define how a piece of software is configured and deployed
-
Catalog The kubernetes manifests that are produced by TheMagic and commited to the Output Repo
Concept Overview
-
Generated config (Kubernetes manifests) in a per-cluster Output git repository.
-
This git repository is then used for GitOps on the actual cluster. GitOps enforces the state independently of whether new config is generated or not (no SPOF).
-
This will most likely also generate the configuration to initially provision the cluster using things like Rancher, Terraform, Crossplane Cluster, etc.
-
The provisioning of the Cluster is out-of-scope for the Platform Configuration management. A design for generating initial config for provisioning will be described in another SDD.
-
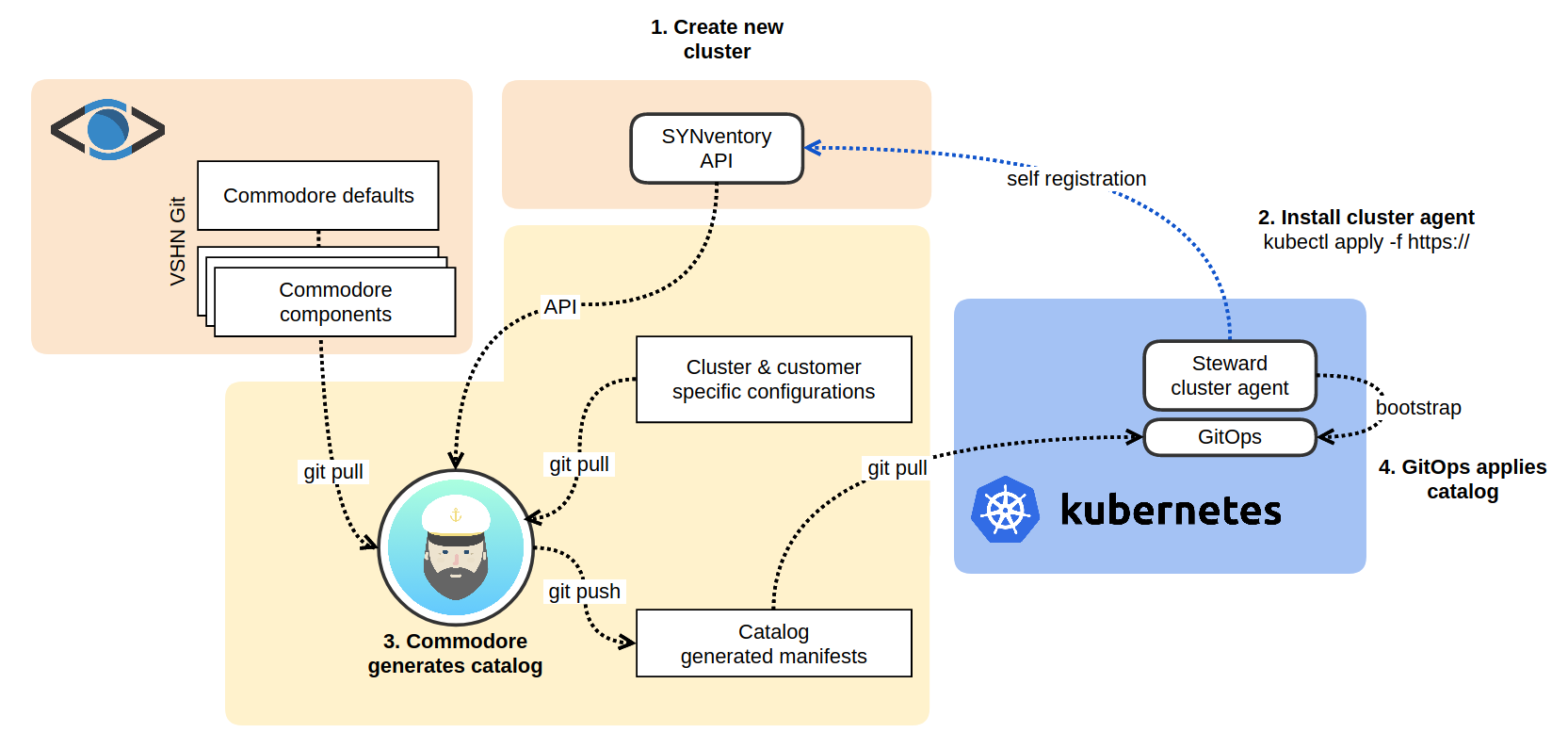
Commodore
Commodore collects all the required configuration (from the SYNventory API and the Input and Config repo) and constructs a Kapitan inventory which is uses to produce the cluster catalog. Commodore is defined in its own SDD 0006 - Commodore Configuration Catalog Compilation.
Kapitan class hierarchy
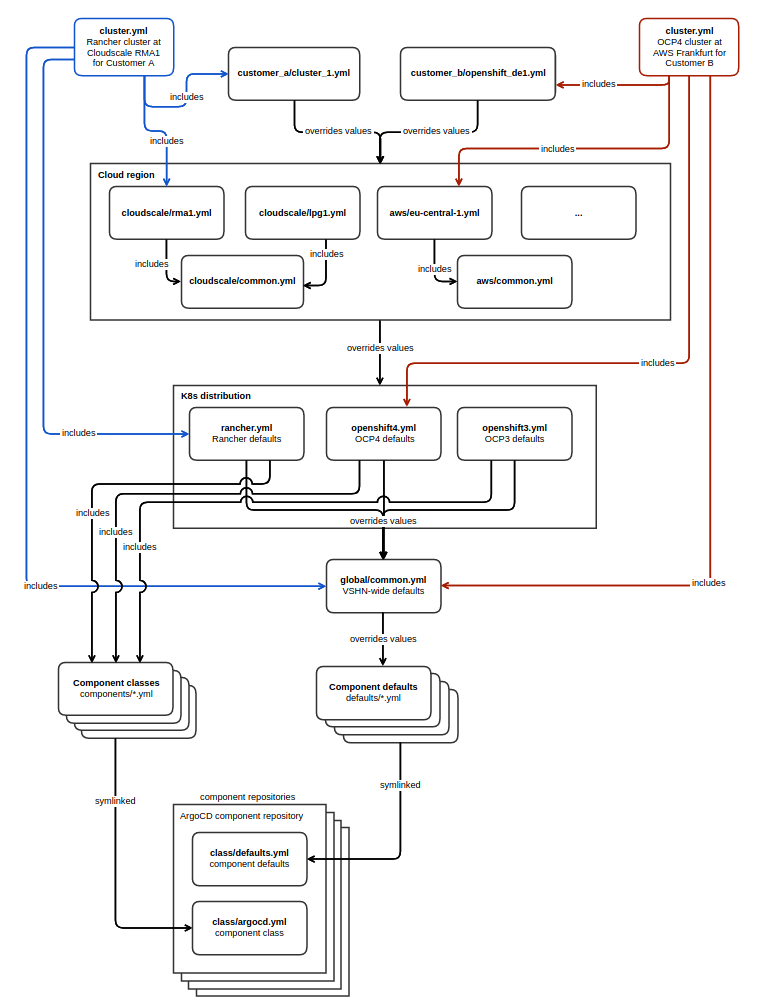
Commodore produces a Kapitan target (a target is the part of the Kapitan
inventory which defines a unit for which configuration should be
rendered) for the target cluster named cluster which includes the
classes global.common, global.<kubernetes-distribution>,
global.<cloud-provider> and <customer-name>.<cluster-name> . The
class hierarchy is defined by the order the classes are included in the
target. The current hierarchy is (weakest to strongest):
-
defaults.* -
global.common -
global.<kubernetes-distribution> -
global.<cloud-provider> -
global.<cloud-provider>.<region> -
<customer-name>.<cluster-name>
Components provide two classes: one which defines how the component’s
templates should be rendered (symlinked to components.<component-name)
and one which defines default parameters for the component (symlinked to
defaults.<component-name>). All available default parameters classes
are included before any configuration classes. This allows users to
include components at any level in the configuration hierarchy without
having to worry about a component’s defaults overriding customization
which is applied earlier in the hierarchy. Component classes can always
access all the configuration, even values that are only defined at a
stronger hierarchy level. The defaults.* notation in the list above
is a short-hand notation for the mechanism in Commodore which includes
each component’s defaults class explicitly.
The current hierarchy places the Kubernetes distribution before the cloud-provider in the configuration hierarchy. This allows selecting which components are included for each Kubernetes distribution which is supported by Commodore. F.e. this hierarchy allows to selectively include only components which have been tested when bootstrapping the configurations for a new Kubernetes distribution.
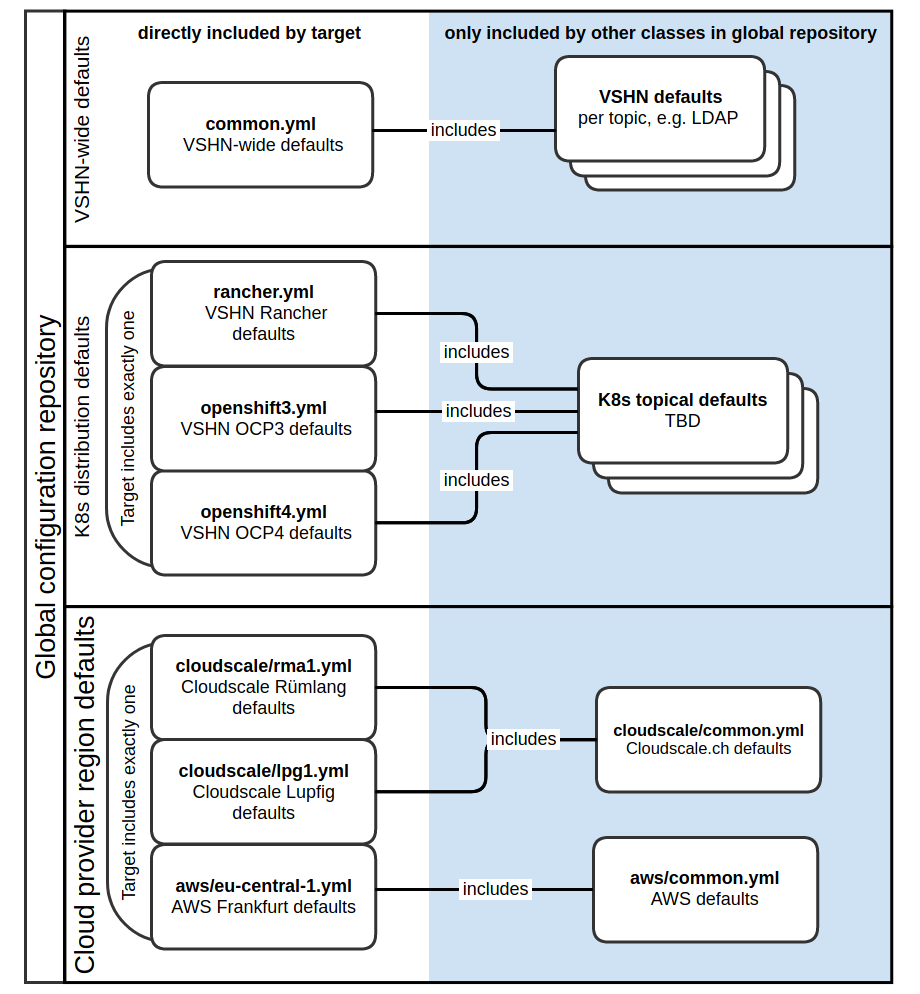
Operators are free to include additional classes at each of the
global.* hierarchy levels, f.e. an operator may choose to not have
one large global.common class but rather split up the fleet-wide
defaults into smaller classes which are included in global.common , as
indicated on the diagram below. The same structure can be applied at the
cloud provider level, where the target only includes
<cloud-provider>.<region>, but operators are free to keep cloud-wide
defaults in one or more classes which are included by each cloud region
class.
The customer level of the hierarchy, which is included via
class <customer>.<cluster> and stored in a separate repository, can
have any structure. The only requirement is that a <cluster>.yml file
exists in the repository for each SYN-managed cluster of the customer.
This <cluster>.yml file can itself include further classes (yaml
files) which are defined in the customer repository by including the
class as <customer>.<filename>. For example, a customer could have a
common.yml which defines their fleet-wide defaults. Each
<cluster>.yml can then include the customer defaults
as <customer>.common .
Job runner
Speculative
The Commodore job runner is responsible for running Commodore for an output repo if any of the inputs change (input repo, config repo, components). The job runner implementation is open to change, an early proposal was to run the Commodore jobs as CI jobs on the output repo. Commodore does include a Dockerfile which can be used to build a Commodore docker image.
Input Repo
The input repo can be hosted on VSHN infrastructure or customer infrastructure. It contains Kapitan class definitions. The classes are available to Commodore/Kapitan as <`customer-name>.<class-name>` . Commodore expects that for each cluster a class <`customer-name>.<cluster-name`> exists in the input repo.
Config Repo
The config repo is hosted on VSHN infrastructure and contains Kapitan
class definitions. The classes are available to Commodore/Kapitan as
global.class-name . Commodore expects that classes global.common ,
global.<cloud-provider> and global.<kubernetes-distribution> to
exist.
Components
Commodore components are hosted in Git repos on VSHN infrastrucutre and
contain Kapitan templates (also "Kapitan
components") and Kapitan classes. Each component class is made
available to Kapitan as components.<component-name> . Commodore
fetches components from Git and ensures that the contained Kapitan
classes are available to Kapitan. Commodore components can also define
"postprocessing" steps which are applied to the Kapitan output to create
the final catalog. Components can utilize most of Kapitan’s features
including Kapitan’s external
dependencies and secret references.
Secret references
Commodore is opinionated in how it supports Kapitan’s secret references: Only references to secrets in Vault (in the KV v2 storage) are supported, and Commodore uses the path to the Kapitan secret file in the reference to determine the name and key in the corresponding Vault secret. References to secrets must always be made in the configuration and never in Kapitan templates directly. This restriction allows Commodore to scan the configuration and create Kapitan secret files for all the references it finds. Secret files are committed to the output repo together with the catalog.
Risks and Mitigations
-
RISK: The design currently depends on the VSHN Git infrastructure
MITIGATION: the dependency on the VSHN Git infrastructure can be softened by having the input, config and component repos replicated on multiple Git hosting platforms' -
RISK: The commodore job runner may depend on an existing GitLab CI infrastructure
-
MITIGATION: It should be possible to migrate the jobs onto other job runner infrastructures (for example Tekton pipelines and triggers).
Drawbacks
The heart of the platform configuration management is an external dependency, Kapitan, which has the drawback that fixing problems in Kapian may be more complicated than in a piece of software that’s maintained by VSHN. Because Kapitan is implemented in Python, the decision was made to implement Commodore itself in Python as well. This has the drawback that Python isn’t particularly containerization friendly. The commodore Docker image is roughly 430MB in size.
References
-
Kapitan: https://kapitan.dev